华为云 TaurusDB 性能挑战赛赛题总结
1 前言
回顾第一次参加性能挑战赛 – 第四届阿里中间件性能挑战赛,那时候真的是什么都不会,只有一腔热情,借着比赛学会了 Netty、学会了文件 IO 的最佳实践,到了这次华为云举办的 TaurusDB 性能挑战赛,已经是第三次参加比赛了,同时也是最“坎坷”的一次比赛。经过我和某位不愿意透露姓名的 96 年小迷妹的不懈努力,最终跑分排名为第 3 名。
如果要挑选一个词来概括这次比赛的核心内容,那非”计算存储分离“莫属了,通过这次比赛,自己也对计算存储分离架构有了比较直观的感受。为了比较直观的体现计算存储分离的优势,以看电影来举个例子:若干年前,我总是常备一块大容量的硬盘存储小电影,但自从家里带宽升级到 100mpbs 之后,我从来不保存电影了,要看直接下载 / 缓冲,基本几分钟就好了。这在几年前还不可想象,如今是触手可及的事实,归根到底是随着互联网的发展,网络 IO 已经不再是瓶颈了。
计算存储分离架构相比传统本地存储架构而言,具有更加灵活、成本更低等特性,但架构的复杂性也会更高,也会更加考验选手的综合能力。
计算存储分离架构的含义:
- 存储端有状态,只存储数据,不处理业务逻辑。
- 计算端无状态,只处理逻辑,不持久化存储数据。
2 赛题概览
比赛整体分成了初赛和复赛两个部分,初赛要求实现一个简化、高效的本地 kv 存储引擎,复赛在初赛的基础上增加了计算存储分离的架构,计算节点需要通过网络传输将数据递交给存储节点存储。
1 | public interface KVStoreRace { |
计算节点和存储节点共用上述的接口,评测程序分为 2 个阶段:
** 正确性评测 **
此阶段评测程序会并发写入随机数据(key 8B、value 4KB),写入数据过程中进行任意次进程意外退出测试,引擎需要保证异常中止不影响已经写入的数据正确性。
异常中止后,重启引擎,验证已经写入数据正确性和完整性,并继续写入数据,重复此过程直至数据写入完毕。
只有通过此阶段测试才会进入下一阶段测试。
** 性能评测 **
随机写入:16 个线程并发随机写入,每个线程使用 Set 各写 400 万次随机数据(key 8B、value 4KB)
顺序读取:16 个线程并发按照写入顺序逐一读取,每个线程各使用 Get 读取 400 万次随机数据
热点读取:16 个线程并发读取,每个线程按照写入顺序热点分区,随机读取 400 万次数据,读取范围覆盖全部写入数据。热点的逻辑为:按照数据的写入顺序按 10MB 数据粒度分区,分区逆序推进,在每个 10MB 数据分区内随机读取。随机读取次数会增加约 10%。
** 语言限定 **
CPP & Java,一起排名
3 赛题剖析
看过我之前《PolarDB 数据库性能大赛 Java 选手分享》的朋友应该对题目不会感到陌生,基本可以看做是在 PolarDB 数据库性能挑战赛上增加一个网络通信的部分,所以重头戏基本是在复赛网络通信的比拼上。初赛主要是文件 IO 和存储架构的设计,如果对文件 IO 常识不太了解,可以先行阅读 《文件 IO 操作的一些最佳实践》。

3.1 架构设计
计算节点只负责生成数据,在实际生产中计算节点还承担额外的计算开销,由于计算节点是无状态的,所以不能够聚合数据写入、落盘等操作,但可以在 Get 触发网络 IO 时一次读取大块数据用作缓存,减少网络 IO 次数。
存储节点负责存储数据,考验了选手对磁盘 IO 和缓存的设计,可以一次使用缓存写入 / 读取大块数据,减少磁盘 IO 次数。
所以选手们将会围绕网络 IO、磁盘 IO 和缓存设计来设计整体架构。
3.2 正确性检测
赛题明确表示会进行 kill -9 并验证数据的一致性,正确性检测主要影响的是写入阶段。
存储节点负责存储数据,需要保证 kill -9 不丢失数据,但并不要求断电不丢失,这间接地阐释了一点:我们可以使用 PageCache 来做写入缓存;正确性检测对于计算节点与存储节点之间通信影响便是:每次写入操作都必须 ack,所以选手必须保证同步通信,类似于 ping/pong 模型。
3.3 性能评测
性能评测由随机写、顺序读、热点读(随机读取热点数据)三部分构成。
随机写阶段与 PolarDB 的评测不同,TaurusDB 随机写入 key 的 16 个线程是隔离的,即 A 线程写入的数据只会由 A 线程读出,可以认为是彼此独立的 16 个实例在执行评测,这大大简化了我们的架构。
顺序读阶段的描述也很容易理解,需要注意的是这里的顺序是按照写入顺序,而不是 Key 的字典序,所以随机写可以转化为顺序写,也方便了选手去设计顺序读的架构。
热点读阶段有点故弄玄虚了,其实就是按照 10M 数据为一个分区进行逆序读,同时在 10M 数据范围内掺杂一些随机读,由于操作系统的预读机制只会顺序预读,无法逆序预读,PageCache 将会在这个环节会失效,考验了选手自己设计磁盘 IO 缓存的能力。
4 架构详解
4.1 全局架构
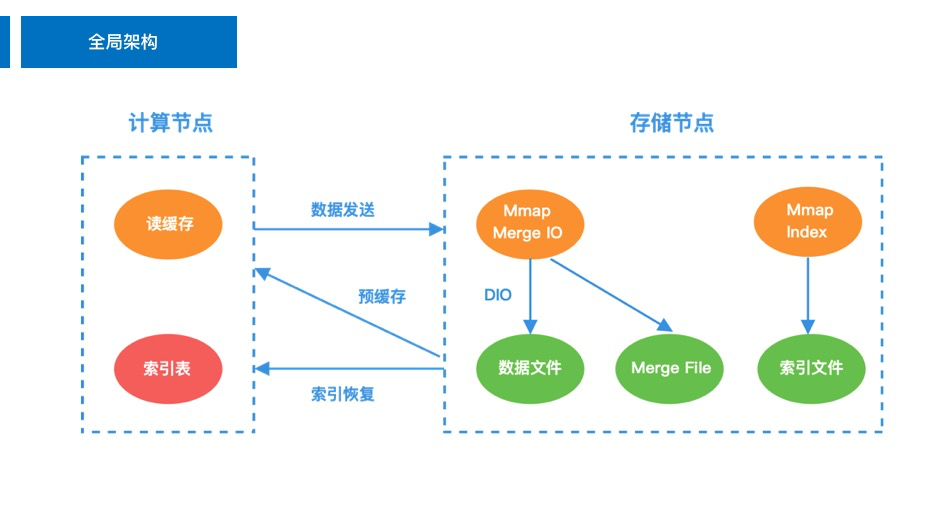
计算存储分离架构自然会分成计算节点和存储节点两部分来介绍。计算节点会在内存维护数据的索引表;存储节点负责存储持久化数据,包括索引文件和数据文件;计算节点与存储节点之间的读写都会经过网络 IO。
4.2 随机写架构
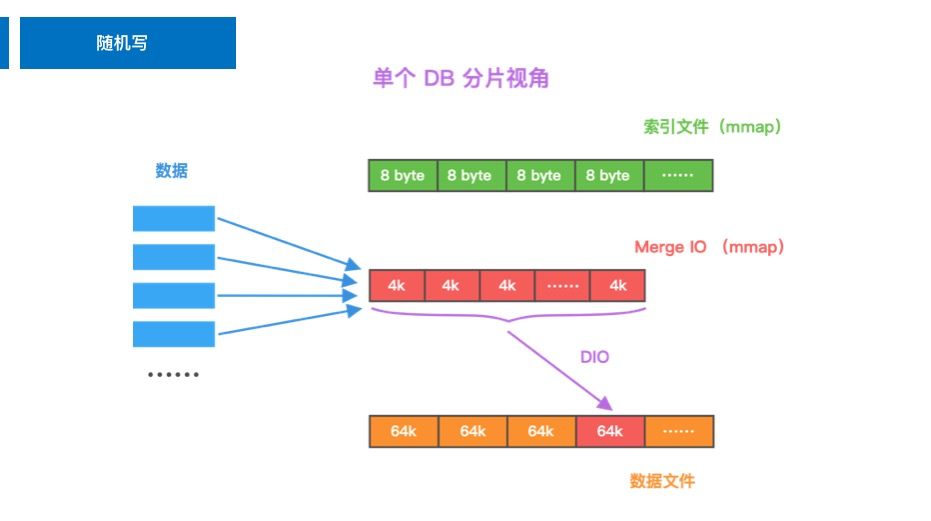
随机写阶段,评测程序调用计算节点的 set 接口,发起网络 IO,存储节点接受到数据后不会立刻落盘,针对 data 和 index 的处理也会不同。针对 data 部分,会使用一块缓冲区(如图:Mmap Merge IO)承接数据,由于 Mmap 的特性,会形成 Merge File 文件,一个数据缓冲区可以聚合 16 个数据,当缓冲区满后,将缓冲区的数据追加到数据文件后,并清空 Merge File;针对 index 部分,使用 Mmap 直接追加到索引文件中。
F: 1. data 部分为什么搞这么复杂,需要聚合 16 个数据再刷盘?
Q: 针对此次比赛的数据盘,实测下来 16 个数据刷盘可以打满 IO。
F: 2. 为什么使用 Mmap Merge IO 而不直接使用内存 Merge IO?
Q: 正确性检测阶段,存储节点可能会被随机 kill,Mmap 做缓存的好处是操作系统会帮我们落盘,不会丢失数据
F: 3. 为什么 index 部分直接使用 Mmap,而不和 data 部分一样处理?
Q: 这需要追溯到 Mmap 的特点,Mmap 适合直接写索引这种小数据,所以不需要聚合。
4.3 热点读 & 顺序读架构
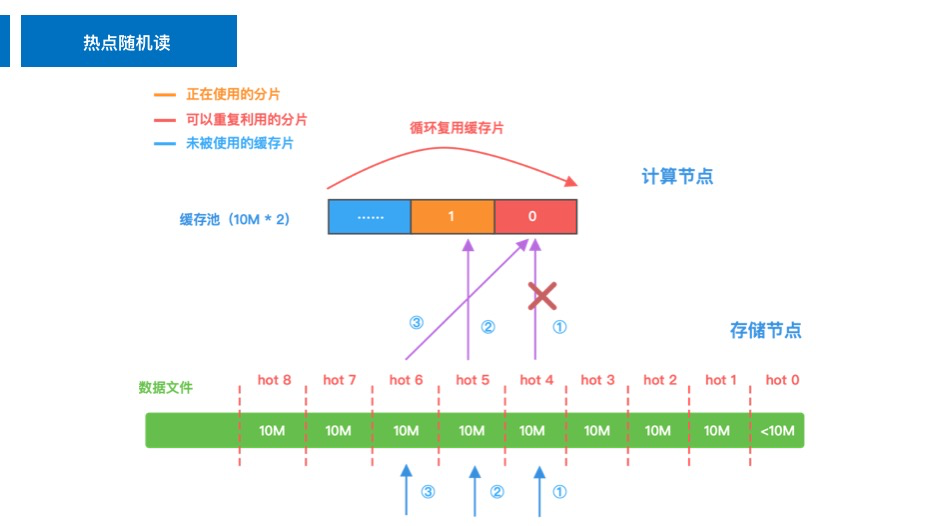
热点读取阶段 & 顺序读取阶段 ,这两个阶段其实可以认为是一种策略,只不过一个正序,一个逆序,这里以热点读为例介绍。我们采取了贪心的思想,一次读取操作本应该只会返回 4kb 的数据,但为了做预读缓存,我们决定会存储节点返回 10M 的数据,并缓存在计算节点中,模拟了一个操作系统预读的机制,同时为了能够让计算节点精确知道缓存是否命中,会同时返回索引数据,并在计算节点的内存中维护索引表,这样便减少了成吨的网络 IO 次数。
4.4 存储设计
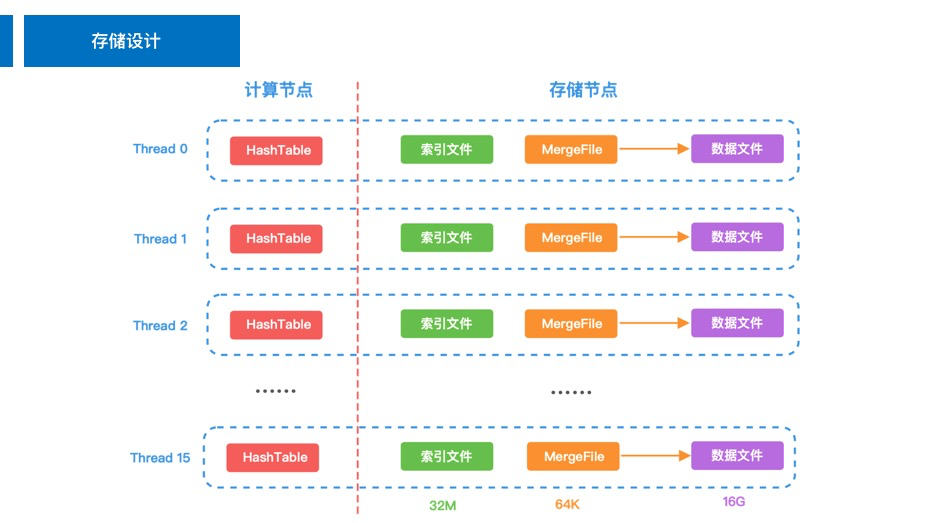
站在每个线程的视角,可以发现在我们的架构中,每个线程都是独立的。评测程序会对每个线程写入 400w 数据,最终形成 16 * 16G 的数据文件和 16 * 32M 左右的索引文件。
数据文件不停追加 MergeFile,相当于一次落盘单位是 64K(16 个数据),由于自行聚合了数据,所以可以采用 Direct IO,减少操作系统的 overhead。
索引文件由小数据构成,所以采用 Mmap 方式直接追加写
计算节点由于无状态的特性,只能在内存中维护索引结构。
4.5 网络通信设计
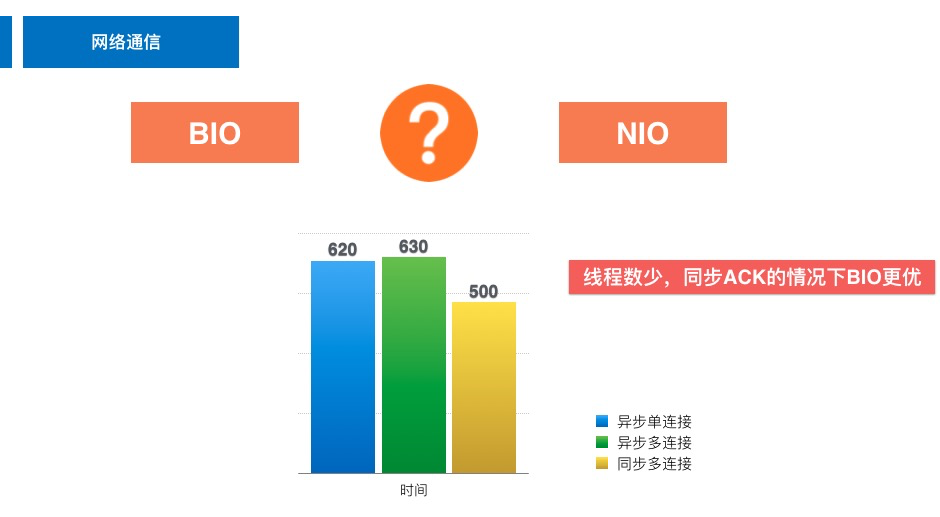
我们都知道 Java 中有 BIO(阻塞 IO)和 NIO(非阻塞 IO)之分,并且大多数人可能会下意识觉得:NIO 就是比 BIO 快。而这次比赛恰恰是要告诉大家,这两种 IO 方式没有绝对的快慢之分,只有在合适的场景中选择合适的 IO 方式才能发挥出最佳性能。
稍微分析下这次比赛的通信模型,写入阶段由于需要保证每次 set 不受 kill 的影响,所以需要等到同步返回后才能进行下一次 set,而 get 本身依赖于返回值进行数据校验,所以从通信模型上看只能是同步 ping/pong 模型;从线程数上来看,只有固定的 16 个线程进行收发消息。以上两个因素暗示了 BIO 将会非常契合这次比赛。
在很多人的刻板印象中,阻塞就意味着慢,非阻塞就意味着快,这种理解是完全错误的,快慢取决于通信模型、系统架构、带宽、网卡等因素。我测试了 NIO + CountDownLatch 和 BIO 的差距,前者会比后者整体慢 100s ~ 130s。
5 细节优化点
5.1 最大化磁盘吞吐量
但凡是涉及到磁盘 IO 的比赛,首先需要测试便是在 Direct IO 下,一次读写多大的块能够打满 IO,在此基础上,才能进行写入缓冲设计和读取缓存设计,否则在这种争分夺秒的性能挑战赛中不可能取得较好的名次。测试方法也很简单,如果能够买到对应的机器,直接使用 iostat 观察不同刷盘大小下的 iops 即可,如果比赛没有机器,只能祭出调参大法,不停提交了,这次 TaurusDB 的盘实测下来 64k、128K 都可以获得最大的吞吐量。
5.2 批量回传数据
计算节点设计缓存是一个比较容易想到的优化点,按照常规的思路,索引应该是维护在存储节点,但这样做的话,计算节点在 get 数据时就无法判断是否命中缓存,所以在前文的架构介绍中,我们将索引维护在了计算节点之上,在第一次 get 时,顺便恢复索引。批量返回数据的优势在于增加了缓存命中率、降低总网络 IO 次数、减少上行网络 IO 数据量,是整个比赛中分量较重的一个优化点。
5.3 流控
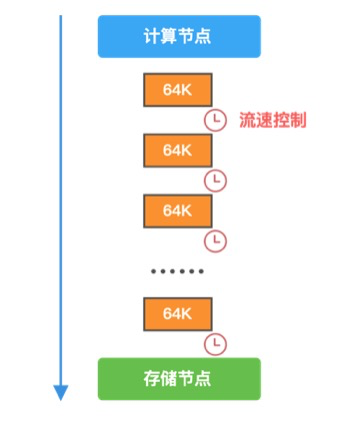
在比赛中容易出现的一个问题,在批量返回 10M 数据时经常会出现网络卡死的情况,一时间无法定位到问题,以为是代码 BUG,但有时候又能跑出分数,不得以尝试过一次返回较少的数据量,就不会报错。最后还是机智的小迷妹定位到问题是 CPU 和 IO 速率不均等导致的,解决方案便是在一次 pong 共计返回 10M 的基础上,将报文拆分成 64k 的小块,中间插入额外的 CPU 操作,最终保证了程序稳定性的同时,也保障了最佳性能。
额外的 CPU 操作例如:for(int i=0;i<700;i++),不要小看这个微不足道的一个 for 循环哦。
流控其实也是计算存储分离架构一个常见设计点,存储节点与计算节点的写入速度需要做一个平衡,避免直接打垮存储节点,也有一种”滑动窗口“机制专门应对这种问题,不在此赘述了。
5.4 预分配文件
在 Cpp 中可以使用 fallocate 预先分配好文件大小,会使得写入速度提升 2s。在 Java 中没有 fallocate 机制,但是可以利用评测程序的漏洞,在 static 块中事先写好 16 * 16G 的文件,同样可以获得 fallocate 的效果。
5.5 合理设计索引结构
get 时需要根据 key 查询到文件偏移量,这显示是一个 Map 结构,在这个 Map 上也有几个点需要注意。以 Java 为例,使用 HashMap 是否可行呢?当然可以,但是缺点也很明显,其会占用比较大的内存,而且存取性能不好,可以使用 LongIntHashMap 来代替,看过我之前文章的朋友应该不会对这个数据结构感到陌生,它是专门为基础数据类型设计的 Map 容器。
每个线程 400w 数据,每个线程独享一个索引 Map,为了避免出现扩容,需要合理的设置扩容引子和初始化容量:new LongIntHashMap(410_0000, 0.99);
5.6 Direct IO
最终进入决赛的,有三支 Java 队伍,相比较 Cpp 得天独厚的对操作系统的灵活控制性,Java 选手更像是带着镣铐在舞蹈,幸好有了上次 PolarDB 比赛的经验,我提前封装好了 Java 的 Direct IO 类库:https://github.com/lexburner/kdio,相比 FileChannel,它能够使得磁盘 IO 效率更高。得知有 Java 选手真的在比赛中使用了我的 Direct IO 类库,也是比赛中实实切切的乐趣之一。
6 失败的优化点
6.1 预读线程先行
考虑到网络 IO 还是比本地磁盘 IO 要慢的,一个本以为可行的方案是单独使用预读线程进行存储节点的磁盘 IO,设计一个 RingBuffer,不断往前预读,直到环满,计算阶段 get 时会消费 RingBuffer 的一格缓存,从而使得网络 IO 和磁盘 IO 不会相互等待。实际测试下来,发现瓶颈主要还是在于网络 IO,这样的优化徒增了不少代码,不利于进行其他的优化尝试,最终放弃。
6.2 计算节点聚合写入缓冲
既然在 get 阶段时存储节点批量返回数据给计算节点可以提升性能,那 set 阶段聚合批量的数据再发送给存储节点按理来说也能提升性能吧?的确如此,如果不考虑正确性检测,这的确是一个不错的优化点,但由于 kill 的特性使得我们不得不每一次 set 都进行 ACK。但是!可以对将 4/8/16 个线程编为一组进行聚合呀!通过调整参数来确定该方案是否可行。
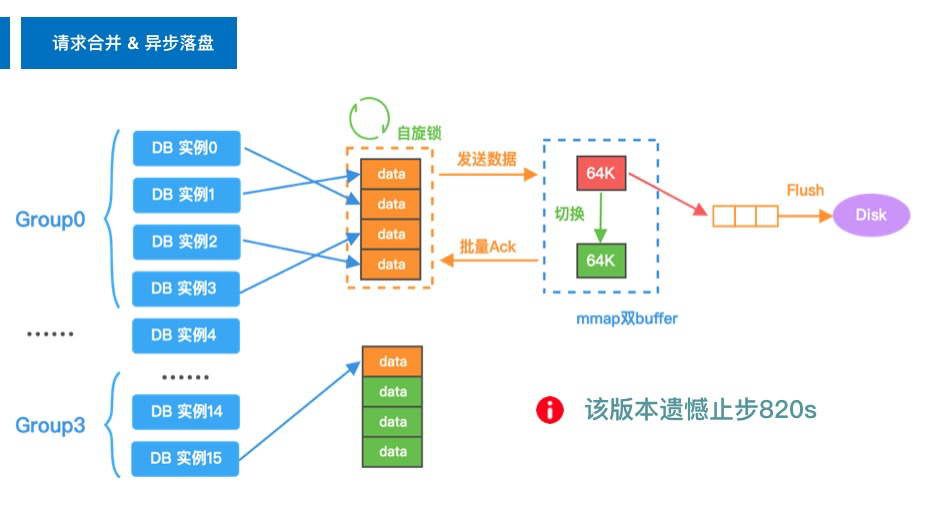
然后事与愿违,该方案并没有取得成效。
7 聊聊比赛吧
之前此类工程性质的性能挑战赛只有阿里一家互联网公司承办过,作为热衷于中间件性能优化的参赛选手而言,非常高兴华为也能够举办这样性质的比赛。虽然比赛中出现了诸多的幺蛾子,但毕竟是第一次承办比赛,我也就不表了。
如果你同样也是性能挑战赛的爱好者,想要在下一次中间件性能挑战赛中有一群小伙伴一起解题、组队,体验冲分的乐趣,欢迎关注我的微信公众号:【Kirito 的技术分享】,也欢迎加入微信技术交流群进行交流 ~
华为云 TaurusDB 性能挑战赛赛题总结


