打开 orika 的正确方式
缘起
架构分层
开发分布式的项目时,DO 持久化对象和 DTO 传输对象的转换是不可避免的。集中式项目中,DO-DAO-SERVICE-WEB 的分层再寻常不过,但分布式架构(或微服务架构)需要拆分模块时,不得不思考一个问题:WEB 层能不能出现 DAO 或者 DO 对象?我给出的答案是否定的。

这张图曾出现在我过去的文章中,其强调了一个分层的要素:服务层 (应用层) 和表现层应当解耦,后者不应当触碰到任何持久化对象,其所有的数据来源,均应当由前者提供。
DTO 的位置
就系统的某一个模块,可以大致分成领域层 model,接口定义层 api,接口实现层 / 服务层 service,表现层 web。
- service 依赖 model + api
- web 依赖 api
在我们系统构建初期,DTO 对象被想当然的丢到了 model 层,这导致 web 对 model 产生了依赖;而在后期,为了满足前面的架构分层,最终将 DTO 对象移动到了 api 层(没有单独做一层)
没有 DTO 时的痛点
激发出 DTO 这样一个新的分层其实还有两个原因。
其一,便是我们再也不能忍受在 RPC 调用时 JPA/hibernate 懒加载这一特性带来的坑点。如果试图在消费端获取服务端传来的一个懒加载持久化对象,那么很抱歉,下意识就会发现这行不通,懒加载技术本质是使用字节码技术完成对象的代理,然而代理对象无法天然地远程传输,这与你的协议(RPC or HTTP)无关。
其二,远程调用需要额外注意网络传输的开销,如果生产者方从数据库加载出了一个一对多的依赖,而消费者只需要一这个实体的某个属性,多的实体会使得性能产生下降,并没有很好的方式对其进行控制(忽略手动 set)。可能有更多痛点,由此可见,共享持久层,缺少 DTO 层时,我们的系统灵活性和性能都受到了制约。
从 DTO 到 Orika
各类博客不乏对 DTO 的讨论,对领域驱动的理解,但却鲜有文章介绍,如何完成 DO 对象到 DTO 对象的转换。我们期待有一款高性能的,易用的工具来帮助我们完成实体类的转换。便引出了今天的主角:Orika。
Orika 是什么?
Orika 是一个简单、快速的 JavaBean 拷贝框架,它能够递归地将数据从一个 JavaBean 复制到另一个 JavaBean,这在多层应用开发中是非常有用的。
Orika 的竞品
相信大多数朋友接触过 apache 的 BeanUtils,直到认识了 spring 的 BeanUtils,前者被后者完爆,后来又出现了 Dozer,Orika 等重量级的 Bean 拷贝工具,在性能和特性上都有了很大的提升。
先给结论,众多 Bean 拷贝工具中,今天介绍的 Orika 具有想当大的优势。口说无凭,可参考下面文章中的各个工具的对比:http://tech.dianwoda.com/2017/11/04/gao-xing-neng-te-xing-feng-fu-de-beanying-she-gong-ju-orika/?utm_source=tuicool&utm_medium=referral
简单整理后,如下所示:
- BeanUtils
apache 的 BeanUtils 和 spring 的 BeanUtils 中拷贝方法的原理都是先用 jdk 中 java.beans.Introspector 类的 getBeanInfo() 方法获取对象的属性信息及属性 get/set 方法,接着使用反射(Method 的 invoke(Object obj, Object... args))方法进行赋值。apache 支持名称相同但类型不同的属性的转换,spring 支持忽略某些属性不进行映射,他们都设置了缓存保存已解析过的 BeanInfo 信息。
- BeanCopier
cglib 的 BeanCopier 采用了不同的方法:它不是利用反射对属性进行赋值,而是直接使用 ASM 的 MethodVisitor 直接编写各属性的 get/set 方法(具体过程可见 BeanCopier 类的 generateClass(ClassVisitor v) 方法)生成 class 文件,然后进行执行。由于是直接生成字节码执行,所以 BeanCopier 的性能较采用反射的 BeanUtils 有较大提高,这一点可在后面的测试中看出。
- Dozer
使用以上类库虽然可以不用手动编写 get/set 方法,但是他们都不能对不同名称的对象属性进行映射。在定制化的属性映射方面做得比较好的有 Dozer,Dozer 支持简单属性映射、复杂类型映射、双向映射、隐式映射以及递归映射。可使用 xml 或者注解进行映射的配置,支持自动类型转换,使用方便。但 Dozer 底层是使用 reflect 包下 Field 类的 set(Object obj, Object value) 方法进行属性赋值,执行速度上不是那么理想。
- Orika
那么有没有特性丰富,速度又快的 Bean 映射工具呢,这就是下面要介绍的 Orika,Orika 是近期在 github 活跃的项目,底层采用了 javassist 类库生成 Bean 映射的字节码,之后直接加载执行生成的字节码文件,因此在速度上比使用反射进行赋值会快很多,下面详细介绍 Orika 的使用方法。
Orika 入门
引入依赖
1 | <dependency> |
基础概念
- MapperFactory
1 | MapperFactory mapperFactory = new DefaultMapperFactory.Builder().build(); |
MapperFactory 用于注册字段映射,配置转换器,自定义映射器等,而我们关注的主要是字段映射这个特性,在下面的小节中会介绍。
- MapperFacade
1 | MapperFacade mapper = mapperFactory.getMapperFacade(); |
MapperFacade 和 spring,apache 中的 BeanUtils 具有相同的地位,负责对象间的映射,也是实际使用中,我们使用的最多的类。
至于转换器,自定义映射器等等概念,属于 Orika 的高级特性,也是 Orika 为什么被称作一个重量级框架的原因,引入 Orika 的初衷是为了高性能,易用的拷贝对象,引入它们会给系统带来一定的侵入性,所以本文暂不介绍,详细的介绍,可参考官方文档:http://orika-mapper.github.io/orika-docs/intro.html
映射字段名完全相同的对象
如果 DO 对象和 DTO 对象的命名遵守一定的规范,那无疑会减少我们很大的工作量。那么,规范是怎么样的呢?
1 | class Person { |
基本字段类型自不用说,关键是打上 <1> 标签的地方,按照通常的习惯,List<AddressDto> 变量名会被命名为 addressDtos,但我更加推荐与 DO 对象统一命名,命名为 addresses。这样 Orika 在映射时便可以自动映射两者。
1 | MapperFactory mapperFactory = new DefaultMapperFactory.Builder().build(); |
这样便完成了两个对象之间的拷贝,你可能会思考:需要我们指定两个类的映射关系吗?集合可以自动映射吗?这一切 Orika 都帮助我们完成了,在默认行为下,只要类的字段名相同,Orika 便会尽自己最大的努力帮助我们映射。
映射字段名不一致的对象
我对于 DTO 的理解是:DTO 应当尽可能与 DO 的字段保持一致,不增不减不改,但可能出于一些特殊原因,需要映射两个名称不同的字段,Orika 当然也支持这样常见的需求。只需要在 MapperFactory 中事先注册便可。
1 | public class Person { |
1 | public class PersonDto { |
完成上述两个结构不甚相似的对象时,则需要我们额外做一些工作,剩下的便和之前一致了:
1 | MapperFactory mapperFactory = new DefaultMapperFactory.Builder().build(); |
这些 .{}[] 这些略微有点复杂的表达式不需要被掌握,只是想表明:如果你有这样需求,Orika 也能支持。上述连续点的行为被称为 fluent-style ,这再不少框架中有体现。
<1> 注意 byDefault() 这个方法,在指定了 classMap 行为之后,相同字段互相映射这样的默认行为需要调用一次这个方法,才能被继承。
<2> classMap()方法返回了一个 ClassMapBuilder 对象,如上所示,我们见识到了它的 field(),byDefault(),register() 方法,这个建造者指定了对象映射的众多行为,还包括几个其他有用的方法:
1 | classMapBuilder.field("a","b");//Person 和 PersonDto 的双向映射 |
更多的 API 可以参见源码
集合映射
在类中我们之前已经见识过了 List
与 List1 | MapperFactory mapperFactory = new DefaultMapperFactory.Builder().build(); |
递归映射
1 | class A { |
Orika 默认支持递归映射。
泛型映射
对泛型的支持是 Orika 的另一强大功能,这点在文档中只是被提及,网上并没有找到任何一个例子,所以在此我想稍微着重的介绍一下。既然文档没有相关的介绍,那如何了解 Orika 是怎样支持泛型映射的呢?只能翻出 Orika 的源码,在其丰富的测试用例中,可以窥见其对各种泛型特性的支持:https://github.com/orika-mapper/orika/tree/master/tests/src/main/java/ma/glasnost/orika/test/generics
1 | public class Response<T> { |
当出现泛型时,按照前面的思路去拷贝,看看结果会如何,泛型示例 1
1 |
|
会发现 responseDto 并不会 Copy 成功吗,特别是在 * 处,你会发现无所适从,没办法把 ResponseDto
1 |
|
Response 中的 String 和 PersonDto 在运行时 (Runtime) 泛型擦除这一特性难住了不少人,那么,Orika 如何解决泛型映射呢?
我们可以发现 MapperFacade 的具有一系列的重载方法,对各种类型的泛型拷贝进行支持
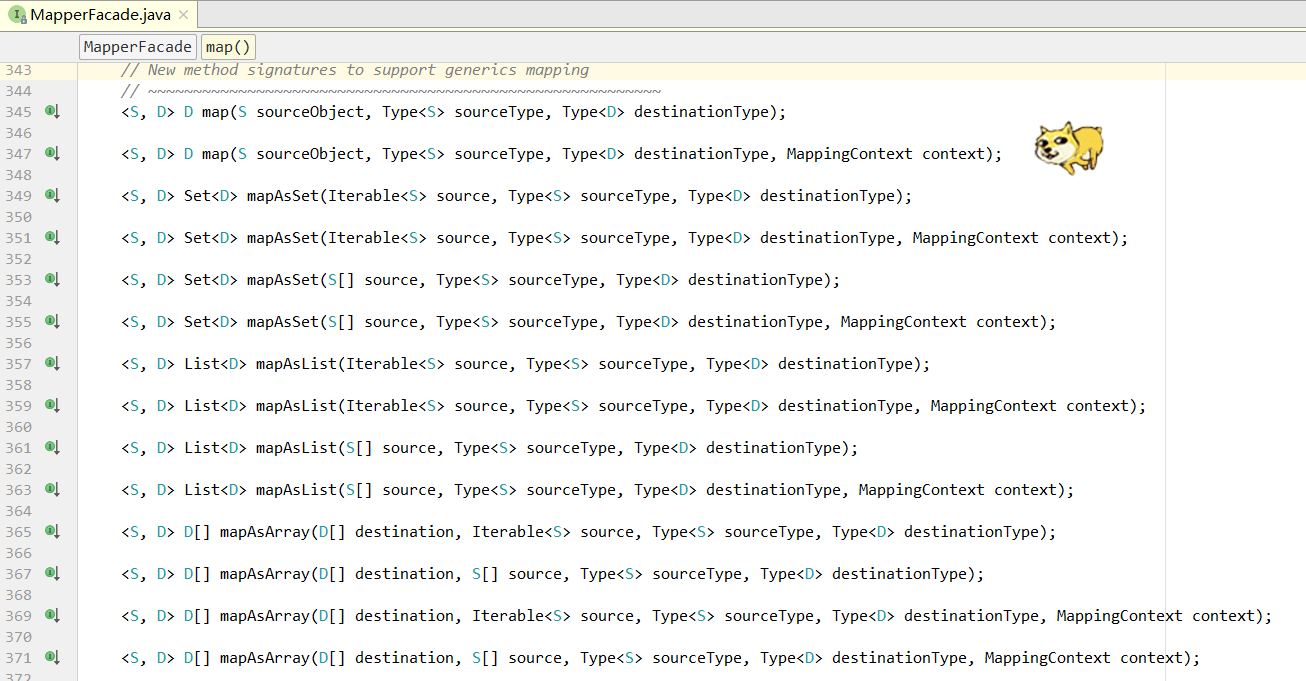
可以看到几乎每个方法都传入了一个 Type,用于获取拷贝类的真实类型,而不是传入.class 字节码,下面介绍正确的打开姿势:
1 |
|
1 |
|
浅拷贝 or 深拷贝
虽然不值得一提,但职业敏感度还是催使我们想要测试一下,Orika 是深拷贝还是浅拷贝,毕竟浅拷贝有时候会出现一些意想不到的坑点
1 |
|
结论:在使用 Orika 时可以放心,其实现的是深拷贝,不用担心原始类和克隆类指向同一个对象的问题。
更多的特性?
你如果关心 Orika 是否能完成你某项特殊的需求,在这里可能会对你有所帮助:http://orika-mapper.github.io/orika-docs/faq.html
怎么样,你是不是还在使用 BeanUtils 呢?尝试一下 Orika 吧!
打开 orika 的正确方式


